背景知识
LSTM原理介绍
{% iframe 'https://datawhalechina.github.io/leeml-notes/#/chapter36/chapter36?id=lstm' 100% 400px %}
pytorch doc
{% iframe 'https://pytorch.org/docs/stable/generated/torch.nn.LSTM.html#torch.nn.LSTM' 100% 400px %}
简单实例
lstm = nn.LSTM(1, 2, 2) # (input_size(feature_num) ,hidden_size,num_layers )
input = torch.randn(4, 1, 1) # (seq_len, batch, input_size(feature_num))
h0 = torch.randn(2, 1, 2) # (num_layers * num_directions, batch, hidden_size)
c0 = torch.randn(2, 1, 2) # (num_layers * num_directions, batch, hidden_size)
output, (hn, cn) = lstm(input, (h0, c0)) # output:(seq_len, batch, num_directions * hidden_size)
# hn = output[-1] , output = [h1,h2,...,hn]
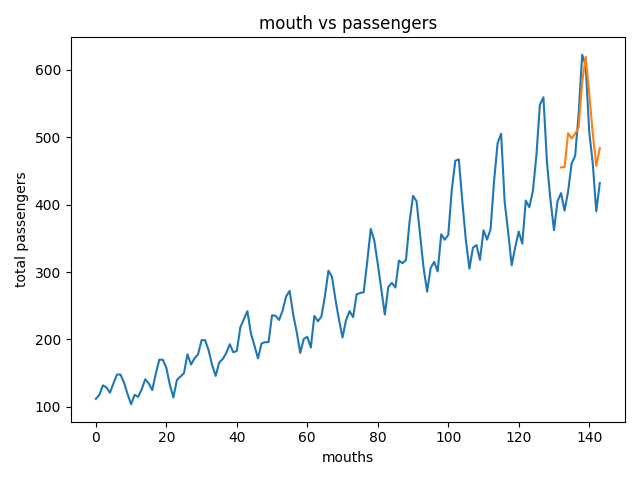
各个参数的理解
- input_size:一个输入中的特征的个数
- hidden_size: 隐藏层节点的个数,如下图
- num_layers: lstm层的个数,默认为1,如果设为2,则第一层的输出[h0,h1,...hn]作为第二层的输入,在计算出最后的输出[h0,h1,...hn]
- seq_len: 一个序列中输入的个数
- batch: 每批处理的样本个数
实例结构图
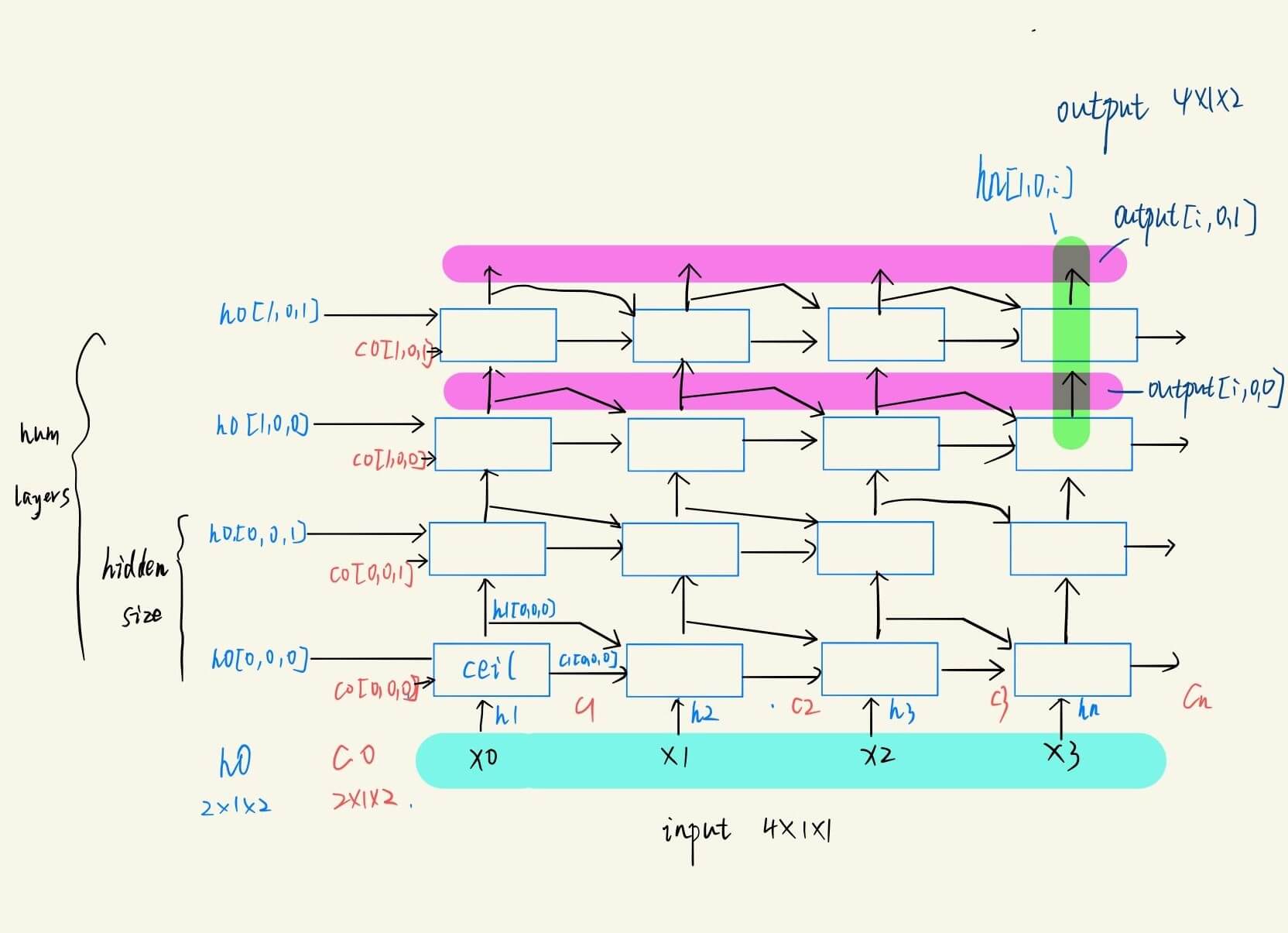
航班预测人数
参考 https://stackabuse.com/time-series-prediction-using-lstm-with-pytorch-in-python/
import torch
import torch.nn as nn
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
# https://stackabuse.com/time-series-prediction-using-lstm-with-pytorch-in-python/
def plot_data(data, pred=None):
plt.title('mouth vs passengers')
plt.xlabel('mouths')
plt.ylabel('total passengers')
plt.plot(data)
if pred is not None:
x = np.arange(132, 144, 1)
plt.plot(x, pred)
plt.show()
def create_io_seq(data, tw):
io_seq = []
for i in range(len(data) - tw):
seq = data[i:i + tw]
lab = data[i + tw:i + tw + 1]
io_seq.append((seq, lab))
return io_seq
class LSTM(nn.Module):
def __init__(self, i_size=1, hid_size=200, o_size=1):
super(LSTM, self).__init__()
self.hidden_layer_size = hid_size
self.lstm = nn.LSTM(i_size, self.hidden_layer_size)
self.linear = nn.Linear(self.hidden_layer_size, o_size)
self.hidden_cell = (torch.zeros(1, 1, self.hidden_layer_size), torch.zeros(1, 1, self.hidden_layer_size))
def forward(self, input_seq):
out, self.hidden_cell = self.lstm(input_seq.view(len(input_seq), 1, -1), self.hidden_cell)
pred = self.linear(out.view(len(input_seq), -1))
return pred[-1]
def train(lstm, data, PATH='./cifar_net.pth'):
loss_func = nn.MSELoss().to(device)
optimizer = torch.optim.Adam(lstm.parameters(), lr=0.001)
print(lstm)
epochs = 150
for i in range(epochs):
for seq, label in data:
seq = seq.to(device)
label = label.to(device)
optimizer.zero_grad()
lstm.hidden_cell = (
torch.zeros(1, 1, lstm.hidden_layer_size).to(device),
torch.zeros(1, 1, lstm.hidden_layer_size).to(device))
y_pred = lstm(seq)
single_loss = loss_func(y_pred, label)
single_loss.backward()
optimizer.step()
if i % 25 == 1:
print(f'epoch: {i:3} loss: {single_loss.item():10.8f}')
torch.save(lstm.state_dict(), PATH)
if __name__ == '__main__':
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
flight = sns.load_dataset('flights')
all_data = flight['passengers'].values.astype(float)
test_data_size = 12
train_data = all_data[:-test_data_size]
test_data = all_data[-test_data_size:]
scaler = MinMaxScaler((0, 10))
train_data_norm = scaler.fit_transform(train_data.reshape(-1, 1))
train_data_norm = torch.FloatTensor(train_data_norm).view(-1)
train_io_seq = create_io_seq(train_data_norm, 12)
lstm = LSTM()
lstm.to(device)
# train(lstm, train_io_seq)
fut_pred = 12
lstm.load_state_dict(torch.load('./cifar_net.pth'))
lstm.cpu()
test_input = train_data_norm[-12:].tolist()
for i in range(fut_pred):
seq = torch.FloatTensor(test_input[-12:])
with torch.no_grad():
lstm.hidden_cell = (torch.zeros(1, 1, lstm.hidden_layer_size),
torch.zeros(1, 1, lstm.hidden_layer_size))
test_input.append(lstm(seq).item())
act_pred = scaler.inverse_transform(np.array(test_input[-12:]).reshape(-1, 1))
plot_data(flight['passengers'], act_pred)
最终结果,蓝色为原始数据,橙红色是预测数据