
概念
batch norm 对于某个神经元的特征值,根据一个batch所有样本在这个神经元位置的特征值均值方差归一化。
layer norm 对于单个样本某一层神经元的特征值,根据这层所有的特征值均值方差归一化
训练过程中,如果发现准确度波动较大或者异常,可以区看看梯度回传值的在多个层的变化是否有异常(突然变大) moco v3
linear probe 冻住原来的网络,仅在模型提取特征后加一个分类头;finetune 端到端的学习,用新数据集,会完全修改原模型参数。
自然语言处理
BERT
简单说就是将一段话中间的某个一个单词覆盖,再通过网络预测这个单词来进行自监督训练,类似完形填空。使用了transformer中的编码器,预测一个单词时可以看到这个单词之前和之后的其他单词。
GPT,GPT-2,GPT-3
GPT
用的是标准的语言模型,给定k个单词,让模型预测这k个单词后边的一个单词,使用的transformer decoder结构,在预测这个单词时,只能看到这个单词的前k个单词,不能看到它之后的单词。
GPT-2
模型结构和gpt基本一致,把模型变大,然后用在了在zero-shot上,做了一些任务。因为时zero-shot,所以需要在训练时提供prompt,然后gpt-2知道prompt要做什么任务。
GPT-3
模型和之前也差不多,但是变得更大了,175 billion 参数,模型非常大,所以训练这个模型也是很难的。所以few-shot微调时就完全不动原来的模型,只是给他prompt让它输出。
OpenAI Codex
基于gpt结构,收集gihub python代码作为训练集重新训练
AlphaCode
在github上收集了一个更大的数据集,包括了所有编程语言的代码,微调数据集是收集了codeforce上的数据作为微调数据集。
结构基于完整的transformer,多头注意力机制中,query个数调整为大于key,value的个数,编码器层数小于解码器层数,基本上是6倍的关系。
生成代码的时候,对于一个个问题生成大量(可以到达百万级别)的候选代码,还训练了一个额外的模型,将这些生成的候选代码聚类,数量最多的类作为第一个结果。
图像任务
ViT
将图片分成块作为transformer的输入
MAE
生成任务,通过将图片分块并随机覆盖掉大部分块,然后恢复整个图片来对图片进行预训练。
MOCO
对比学习,无监督学习
对比学习主要思想是,类似的图片在空间向量上也应该更接近,对比学习一般通过训练一个样本(query)和一个正样本(key+)类似,和一群负样本(key)不相似来实现。
正样本通过裁剪,数据增强,同一个物体的不同角度等方式生成,剩下的其他所有图片都是负样本。
moco的 query key+ 通过同一张图片不同的裁剪获得,
moco负样本利用一个队列字典实现,每次迭代都将本次得到的所有key+都加入到队列中。
moco 的 query 和 key不使用相同的编码器,key的编码器是一个动量编码器 fk = m * fk + (1-m) * fq。fk是key的编码器变量,m设置为一个很大的数字(0.999),这样,key编码器的参数更新的就不会很快,同时也保证了字典内样本的相对一致性(样本是否通过同一个编码器)。
其中infoNCE损失函数在交叉熵上多了一个温度超参数,然后类别数量变成了字典大小。
# f_q, f_k: encoder networks for query and key
# queue: dictionary as a queue of K keys (CxK)
# m: momentum
# t: temperature
f_k.params = f_q.params # initialize
for x in loader: # load a minibatch x with N samples
x_q = aug(x) # a randomly augmented version
x_k = aug(x) # another randomly augmented version
q = f_q.forward(x_q) # queries: NxC
k = f_k.forward(x_k) # keys: NxC
k = k.detach() # no gradient to keys
# positive logits: Nx1
l_pos = bmm(q.view(N,1,C), k.view(N,C,1))
# negative logits: NxK
l_neg = mm(q.view(N,C), queue.view(C,K))
# logits: Nx(1+K)
logits = cat([l_pos, l_neg], dim=1)
# contrastive loss, Eqn.(1)
labels = zeros(N) # positives are the 0-th
loss = CrossEntropyLoss(logits/t, labels)
# SGD update: query network
loss.backward()
update(f_q.params)
# momentum update: key network
f_k.params = m*f_k.params+(1-m)*f_q.params
# update dictionary
enqueue(queue, k) # enqueue the current minibatch
dequeue(queue) # dequeue the earliest minibatch这些无监督模型,主要目的都是为了找到一个好的预训练结果,从而使下游的任务获得一个更好的结果。
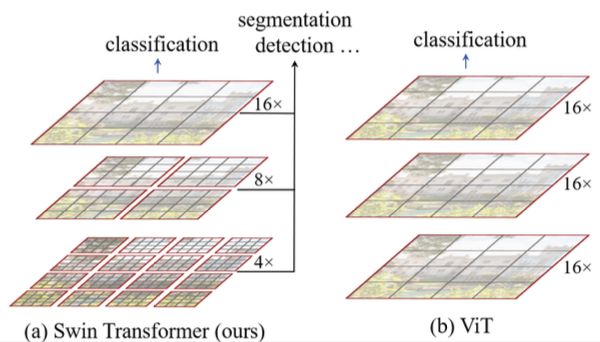
Swin Transformer
相对于vit能更好的获取多尺度特征,swin transformer 在一个窗口(MxM)内算自注意力,可以把窗口合并获得大范围的特征。它首先分别在一个最小的patch里(h/4*w/4 * 4*4*3)做嵌向量得到h/4 * w/4 * C,然后进行自注意力,进行patch合并操作将相邻的4个patch合并到一起(4个patch的C向量拓展合并成4C)得到 h/8 * w/8 * 4C 降维得到 h/8 * w/8 * 2C,之后进行自注意力操作,自注意力有两步,第一步它分别在每个MxM的窗口内做自注意力操作,然后使用滑动窗口获得不同窗口之间的注意力(简单说就是把第一步中分布在不同窗口的区域分配给同一区域)
CLIP
无监督训练,对比学习,看图片和文本是否匹配来训练。

图片编码器本文中用了不同大小的resnet和vit(vit好像更好?),文本编码器就是transformer。对比学习在一个batch(本文中的batch很大是32768,还tm叫minibatch🥲)中进行。使用moco的方法是否有提升?
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2这里的损失函数就是正常的分类任务里的交叉熵,类别数量是一个batchsize的大小。
zero shot做分类任务是将图片编码获得特征,将文字prompt(好像发展成一个方向了。。)成句子编码获得特征,然后算两个特征的匹配度,找到最最配的句子后获得其中的类别。另外是否可以直接通过图片的特征获得文字内容呢?
论文内few-shot(one、two、three shot)比zero-shot要差主要原因可能是few-shot用的linear probe(冻住原来的网络,仅在特征后面加一个分类头,由于分类头初始化随机,而fews-hot还数量很少还没学习好。)
DETR

实现了端到端的目标检测任务,把cnn抽取的特征放到transformer里生成n(本文n取100)个框,计算这n个框与ground truth 的loss,生成一个cost matrix,通过匈牙利算法获得最优解。根据最优解去算loss以及梯度更新。
视频任务
综述 A Comprehensive Study of Deep Video Action Recognition
双流网络

视频理解方向,把视频分为空间流和时间流分别放入网络获取特征。空间流就是把视频每帧作为输入,就是当作基本的图像进行处理。时间流的输入是光流,光流就是视频连续两帧之间的变化,数学上分为水平方向位移和竖直方向位移两个维度,动作需要较长的时间变化信息,所有需要把多张光流合并到一起进行处理,第一种方式就是光流图直接叠加,就是两张光流图对应位置的数值求和。第二种是,第一张光流图p1点运动到了p2,然后找第二张光流图从p2开始的运动轨迹,把他们加起来。但本文中第一种方法结果较好。
如果单一的网络结果不是很好,就可以考虑给网络输入其他的信息形成多流网络的结构去解决问题。
I3D
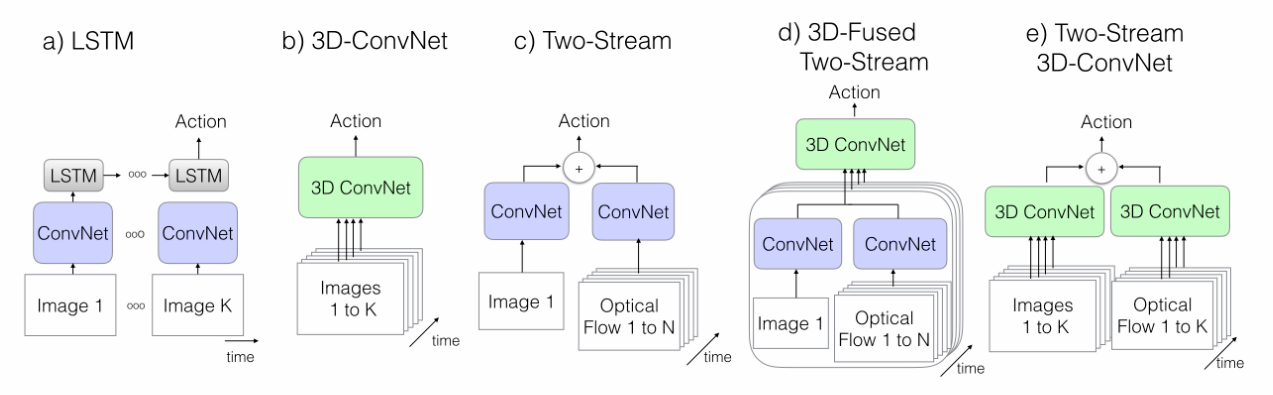
主要是提供了一个大的数据集,然后双流网络中的2d卷积变成3d卷积。
Inflat 2D into 3D:把2d网络变成3d网络,直接把所有的2d卷积核变成3d的卷积核,2d的pooling层也变成3d的pooling层。
bootstrapping 3d from 2d:把2d网络中预训练好的参数复制到inflated后的3d网络中,把2d的参数分别复制到3d网络的每个时刻2d层,最后在除3d层中2d层的个数(也就是时间的个数)。 经过这样后,把一个图片复制成一个视频,把视频输入到3d网络中的结果应该和把图片输入到2d网络中的结果是一样的。
在时间维度上,不做下采样。
SlowFast Networks
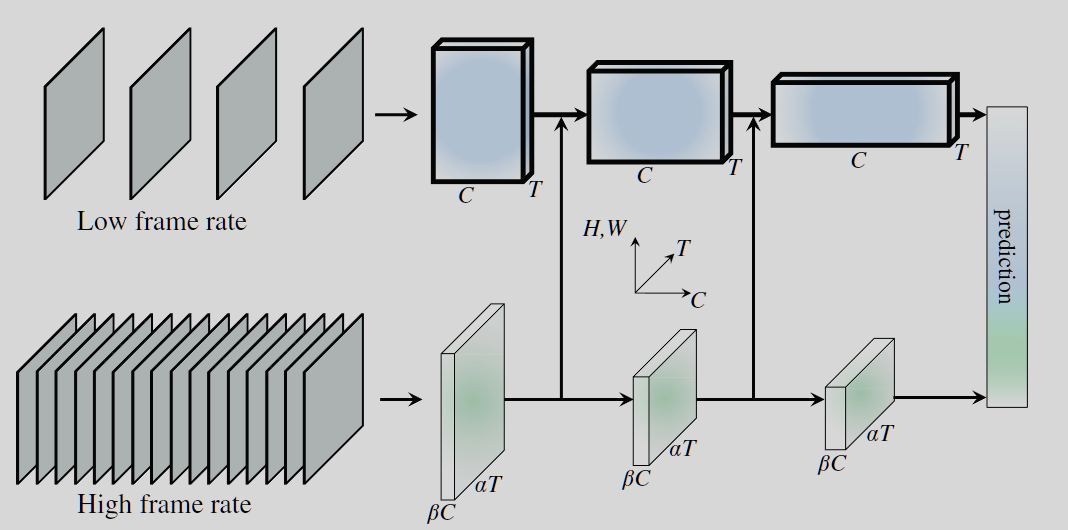
提出了一种快慢结合的网络来用于视频分类。其中一路为Slow网络,输入为低帧率图片,用来捕获空间语义信息,slow网络比较复杂。另一路为Fast网络,输入为高帧率图片,用来捕获运动信息。而且Fast网络是一个轻量级的网络,其channel比较小。SlowFast网络受到生物学中灵长类视觉系统中视网膜节细胞的启发。在视网膜节细胞中,80%是P-cell, 20%是M-cell,其中M-cell,接受高帧率信息,负责响应运动变化,对空间和颜色信息不敏感。P-cell处理低帧率信息,负责精细的空间和颜色信息。而这正对应于SlowFast网络的两路。
Time Transformer
把transformer用在video上,video transformer ,论文试验了多种结构
 直接在空间上做attention,类似vision transformer,把视频分成图片分别做attention
直接在空间上做attention,类似vision transformer,把视频分成图片分别做attention直接在时空上做attention。耗费资源大
先在小窗口算attention,再在整体上做attention(有点类似swin transformer)
先在时间上做attention,再在空间上做attention
分别在时间、空间横向、空间纵向做attention
第二种耗费资源太多,在有限的资源上得到的最优的结果的是第三种结构。
知识蒸馏

hard label ,soft label :给定一张马的照片,这张照片是马的概率是1,是驴,汽车或者其他物体的概率全为0,这叫 hard target,这种概率是不科学的,它忽略的不同物体之间的不同程度,驴肯定是比汽车更像马的。所以soft target,对于马,驴,汽车的概率分别是0.7,0.25,0.5。说明驴比汽车更像马。
soft label 包含了更多的信息。可以用教师网络训练得到的label,这种lable包含了更多信息,来训练学生网络。可以提高训练的效率。
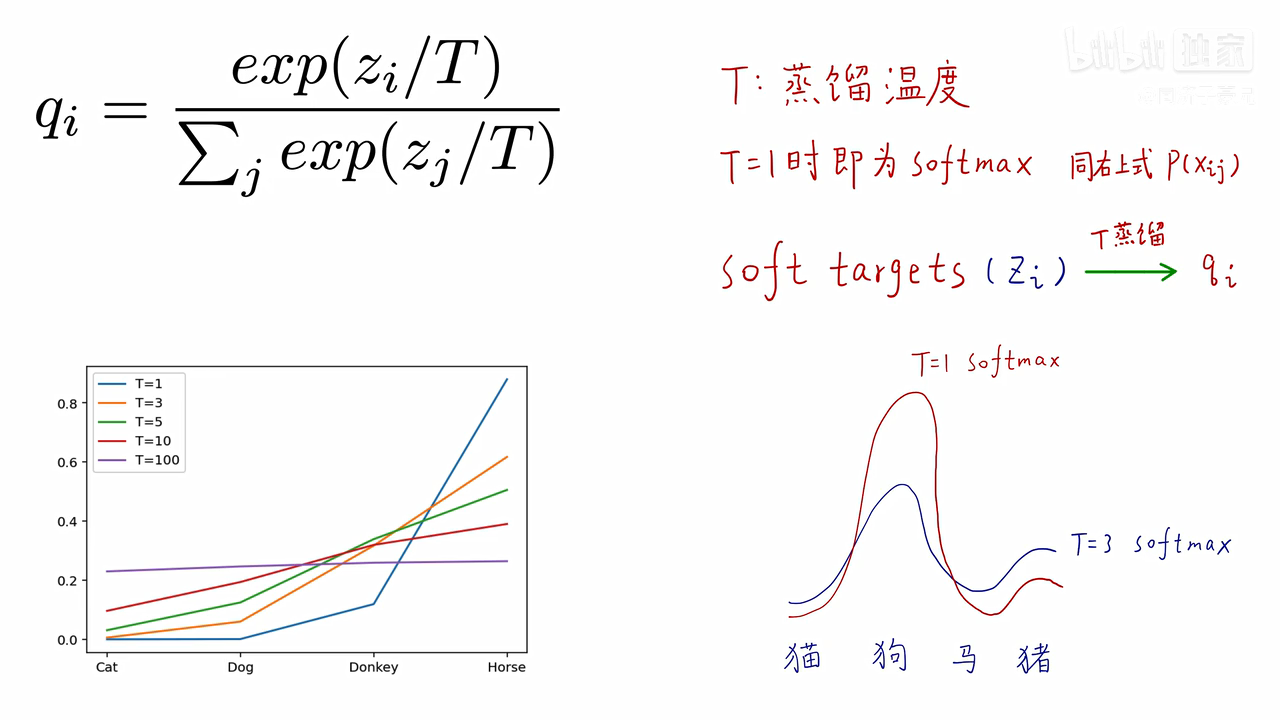
蒸馏温度,温度越高,不同种类之间的概率差别越小
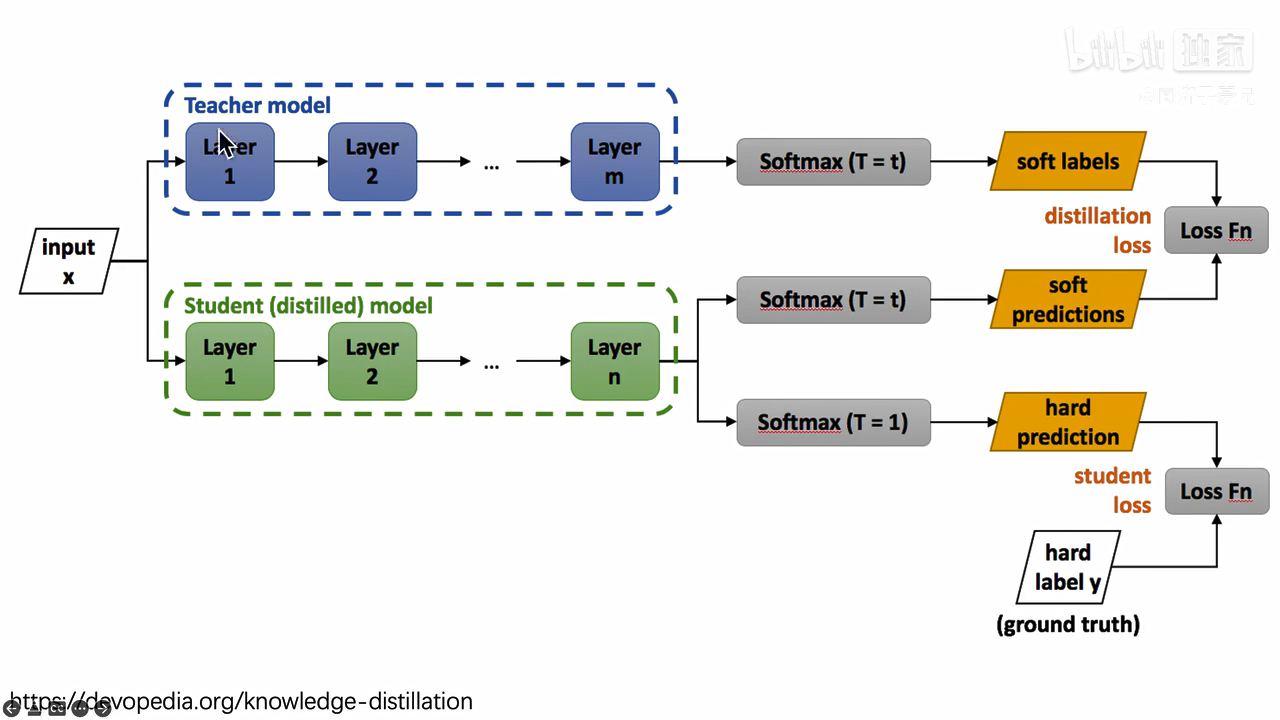
最终训练 loss 是 蒸馏loss 和学生loss加权和。
CLIP改进工作
Lseg
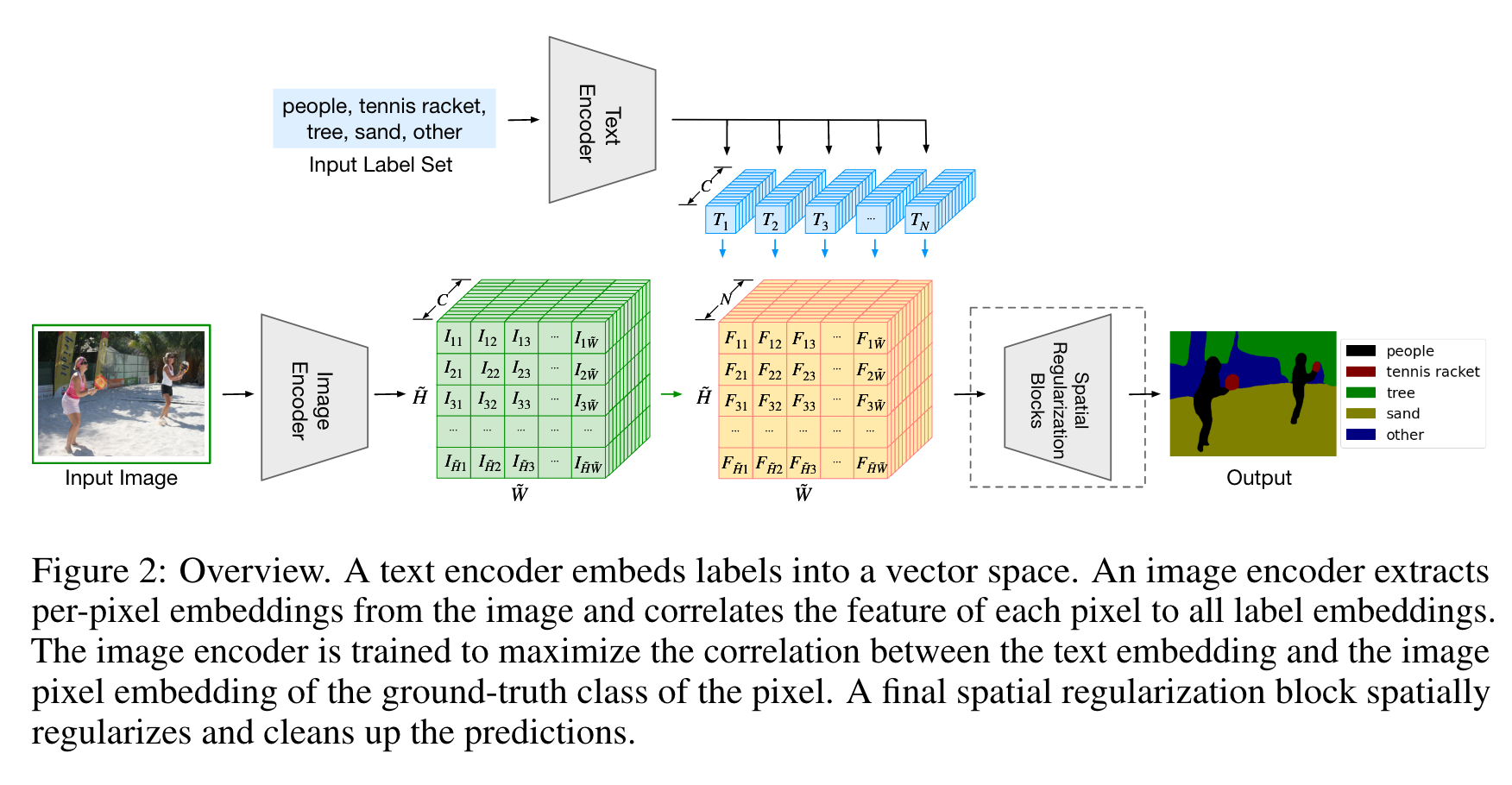
文本编码器就是clip训练好的文本编码器。图像编码器这个用的 vit+decoder(比clip的好用)。两个特征相乘得到的结果中,N就是文本标签的数量也就是类别。在经过一个可学习的块后最终得到实例分割的结果,有监督学习,根据训练集的标签算cross entropy loss 训练模型。
GroupViT
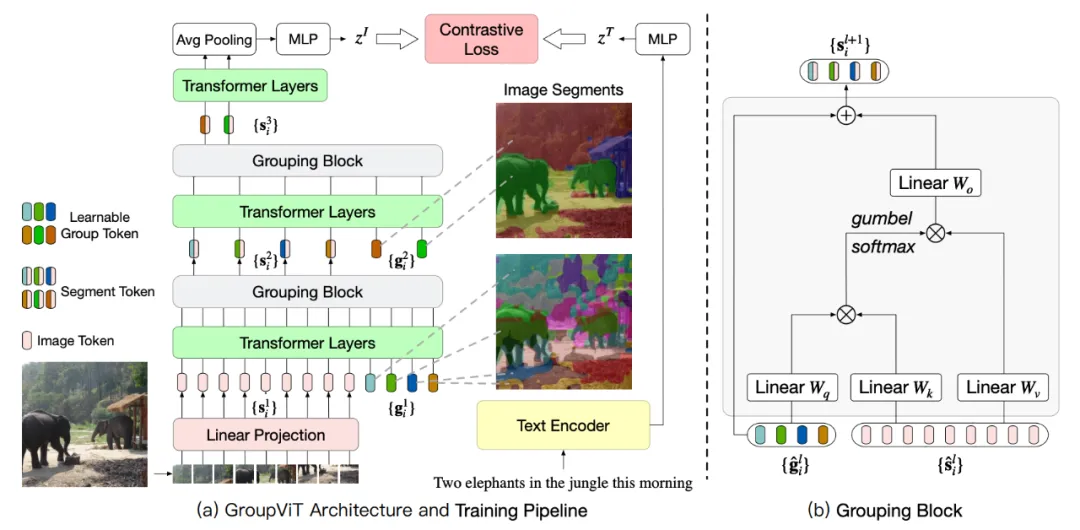
GroupViT是一个分层聚类的结构(gi表示聚类中心),开始阶段将像素分组为局部对象,后来的阶段进一步将这些局部对象合并成整体。最后获得8个聚类后平均池化接一层mlp后作文图像的特征,来和文本特征像CLIP一样算对比学习 loss 来训练。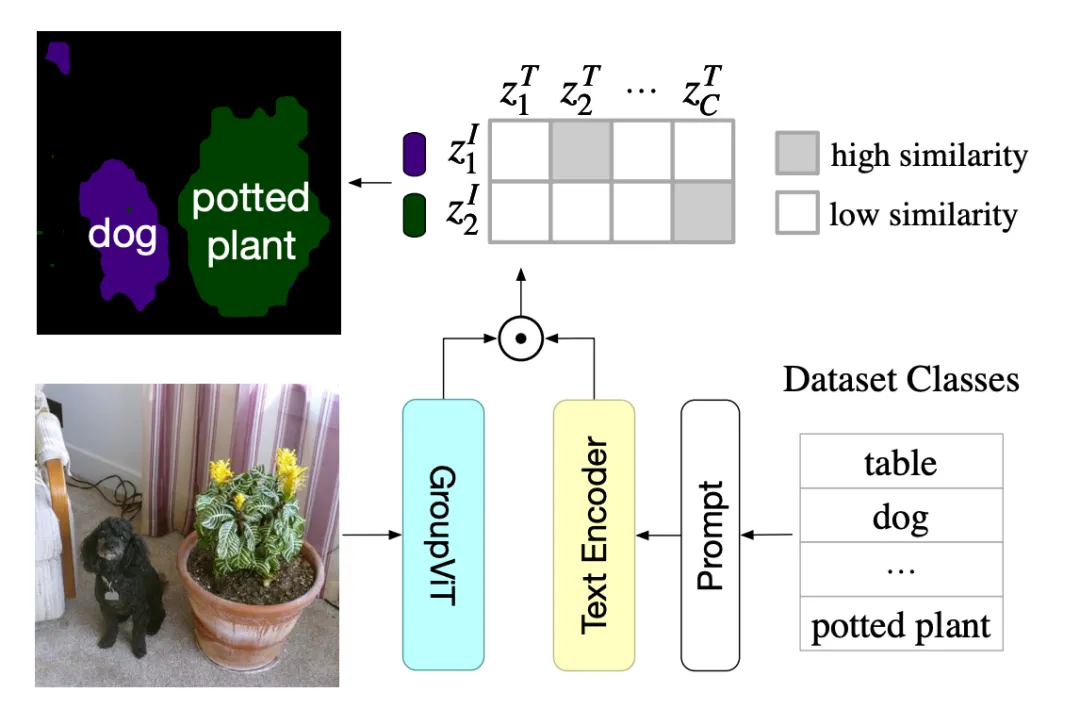
推理时,将图片输入到GroupViT获得8个group embedding,然后这些特征和文本编码的特征计算相似度,看这8个聚类分别代表文本的哪一类。
哪些像素对应哪个类别,这里其实是patchlevel的分割而不是pixellevel的分割。然后示意图是通过插值的方法得出来的。
个人猜测是根据聚类好的的group embedding 和图片的patch embedding 相似去分类,看那些patch 图片的特征和这些group 的特征中的哪一个更接近,然后把这个patch就分给这个类。
ViLD
GLIP
CLIPasso
将图片用带有语义信息最简化的笔画表示出来
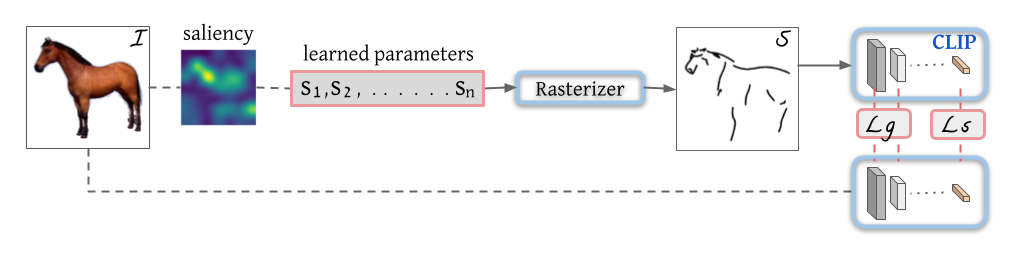
saliency(显著性) 初始化对结果的影响很大,这里采用了一个基于saliency的初始化方式,把图片输入给ViT,得到最后一层多头自注意力的特征取加权平均生成saliency map,在图上更显著的区域采点初始化。
Rasterizer(光栅化)将学习到的参数画出来。
Ls 算原始图片经过Clip图片编码器得到的最后的特征与简笔画经过Clip过Clip图片编码器得到的最后的特征的差别(语义信息差异)。
Lg 算原始图片经过Clip图片编码器得到的前几层特征与简笔画经过Clip过Clip图片编码器得到的前几层特征的差别(空间位置信息差异)。
CLIP4clip
ActionCLIP
CLIP-ViL
AudioCLIP
PointCLIP
DepthCLIP
多模态